Few months ago, we had the amazing opportunity to deploy SexiGraf in a *BIG* company. Think petabytes scale.
In the past, we have already been challenged to make our tool scalable, but not that much:
- 60+ vCenter
- 7000+ ESX
- 200000+ VM
- 18000+ datastores
- 1000+ clusters
- 200ms+ network latency for half vCenters
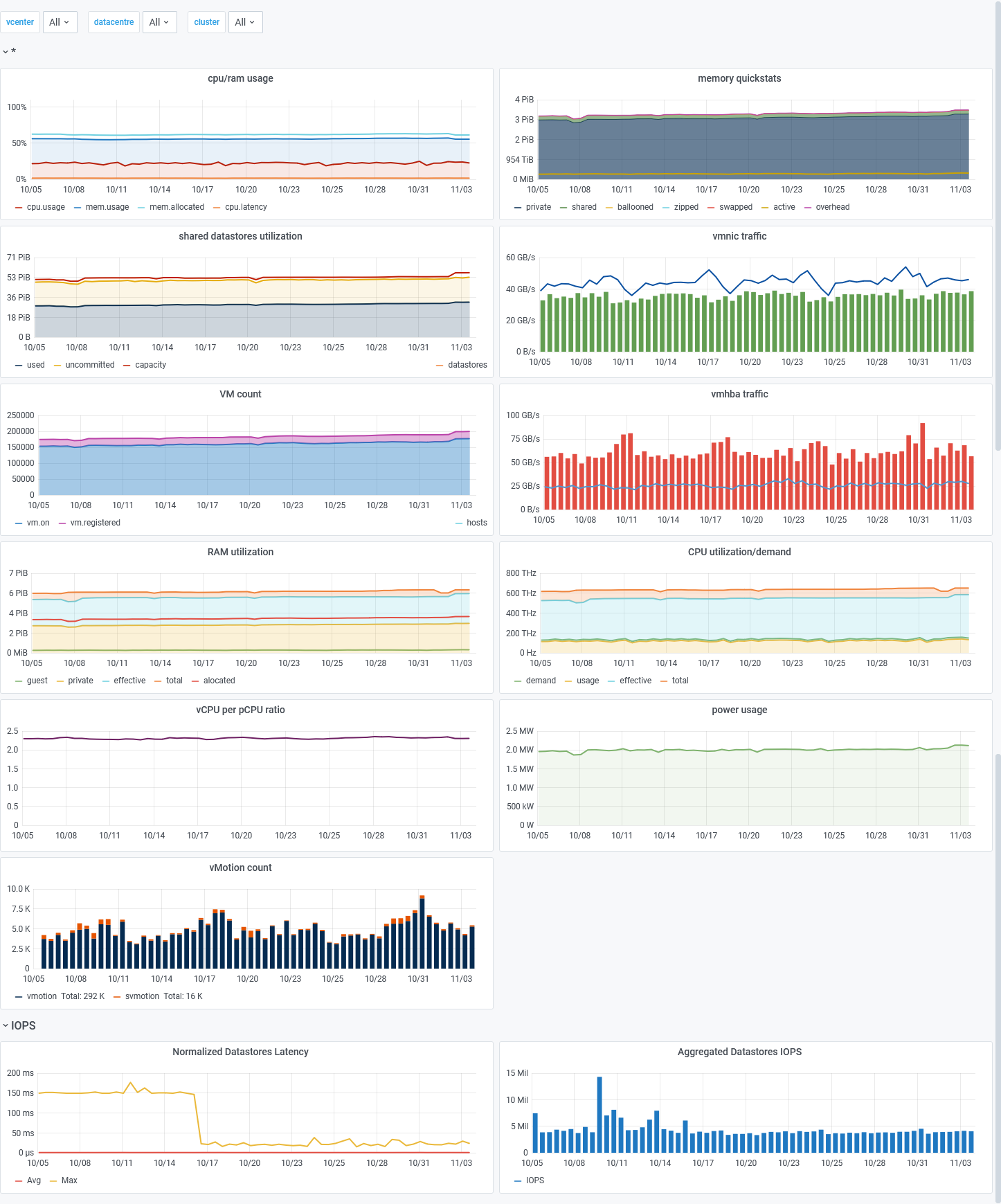
After many hours of hard work, almost total rewrite of our code and a massive use of hash tables, we are proud to show you a sneak peek of the next SexiGraf version (0.99f) connected to 60+ vCenters:
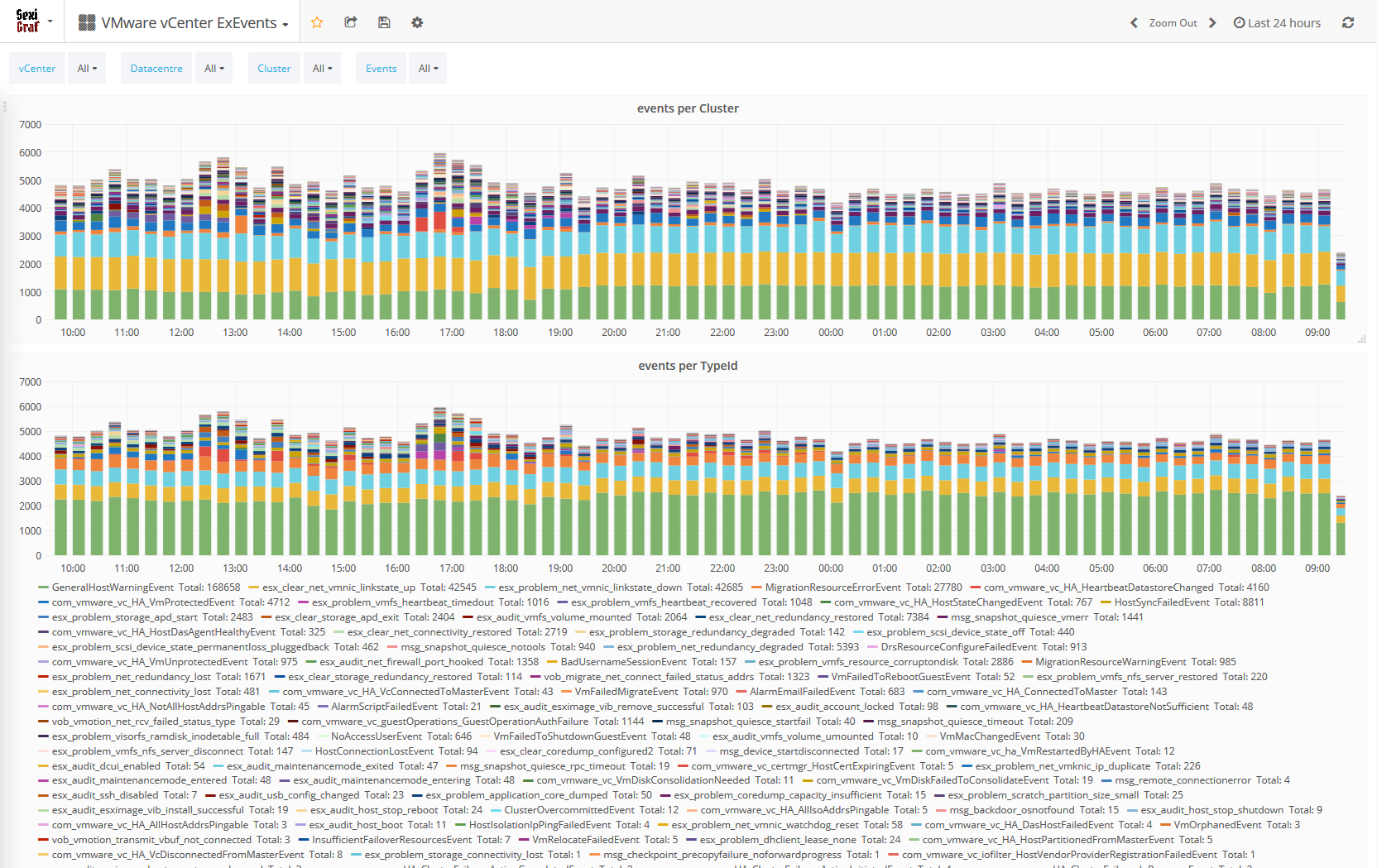
And since the customer hasn’t figured out how to handle syslog for it’s 7000+ ESX yet, we added a “bad” events dashboard (warnings and errors) grouped by clusters:
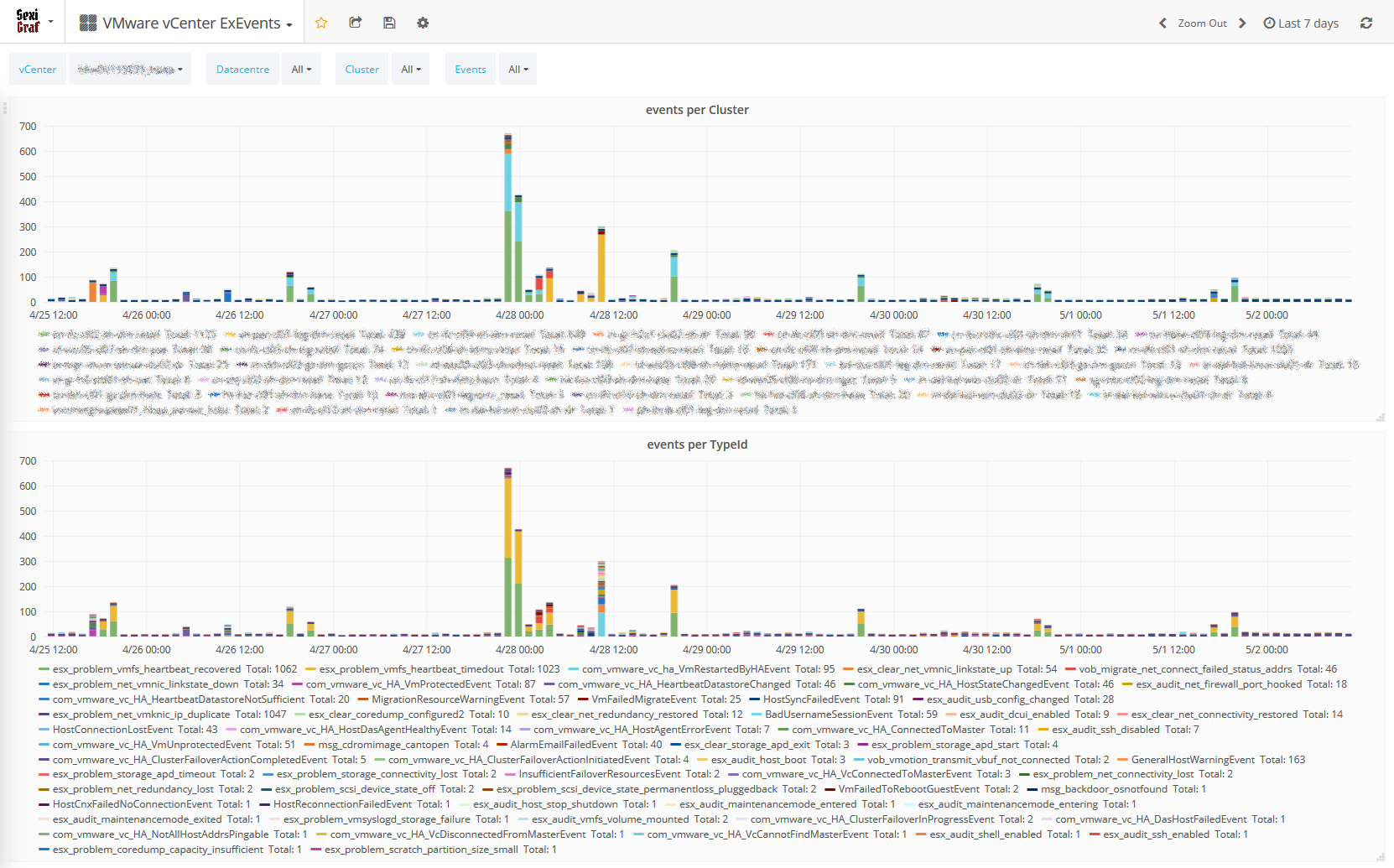
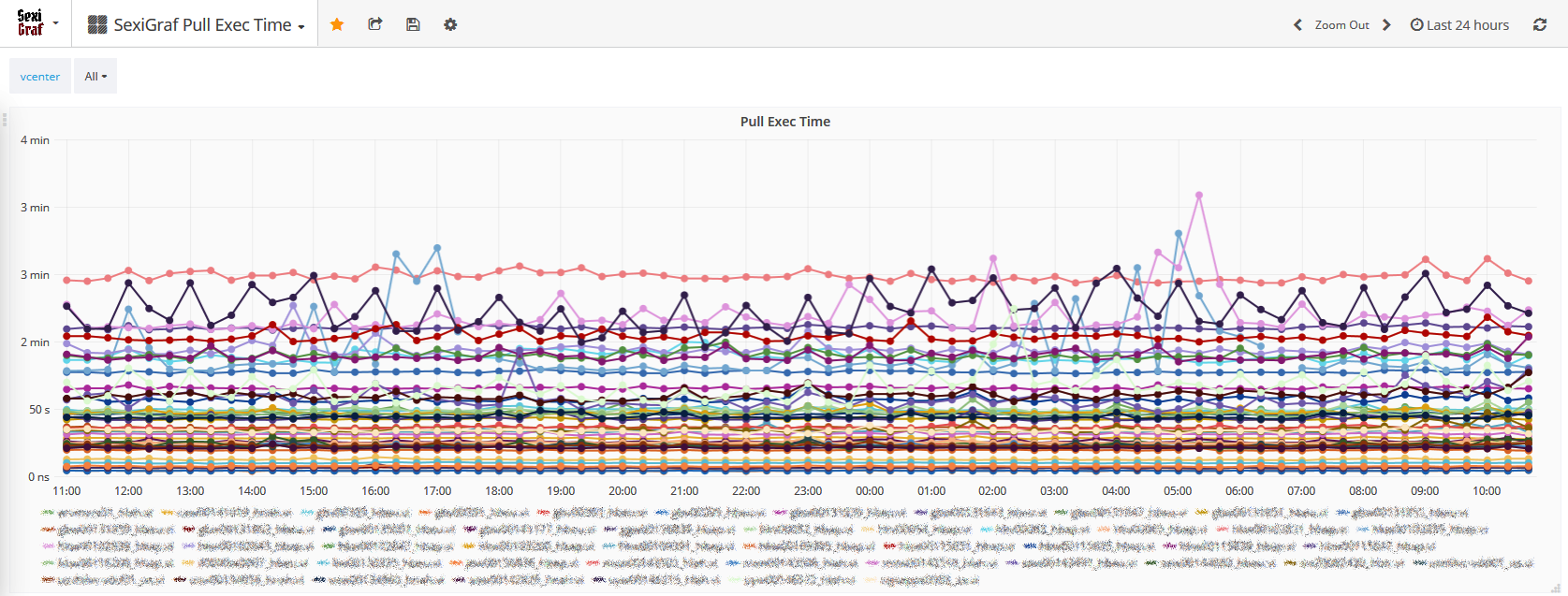
With a single VM (24 vCPU and 64GB vRAM) the polling is only taking 3 minutes (maximum) to complete:
Stay tuned 😉