vSAN Monitor vSAN Monitor SFTT Resync & Health Disk Latency Space Usage Report Disk Utilization vSAN Monitor Network vSAN SMART Stats
Since SexiGraf 0.99h the metrics used in the various vSAN dashboards are now collected every 5 minutes because we had to move from the QueryVsanStatistics API method of HostVsanInternalSystem to the “new” VsanPerfQueryPerf of the VsanPerformanceManager for scalability reasons. This new source is unfortunately limited to 5min intervals. If you need realtime, you got vsantop since vSphere 6.7 Update 3. We also removed some unpopular or unused dashboards but we also added features to the new ones. The previous dashboards page is archived here.
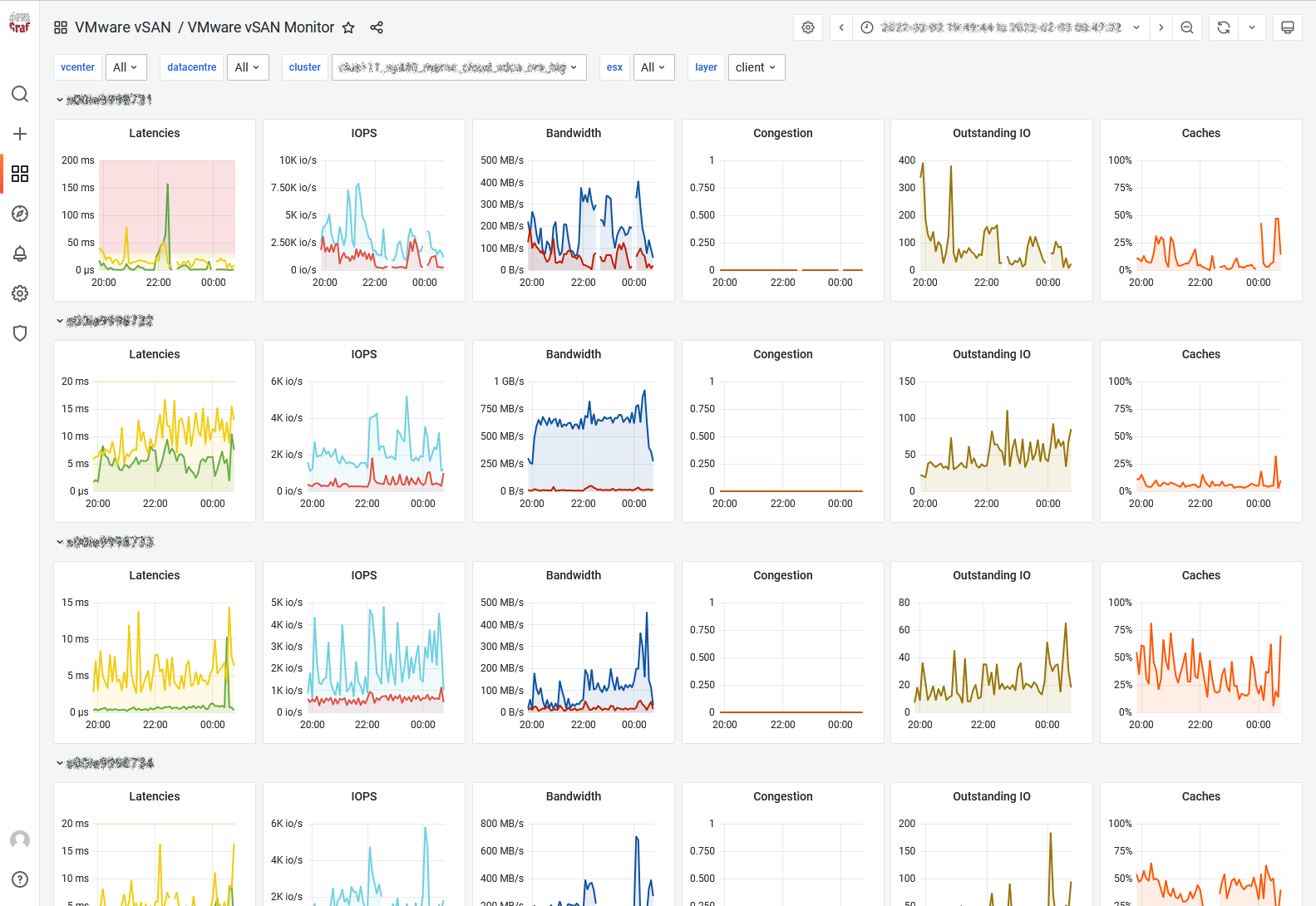
vSAN Monitor
If this dashboard looks familiar this is because it is heavily inspired from vSAN Observer:
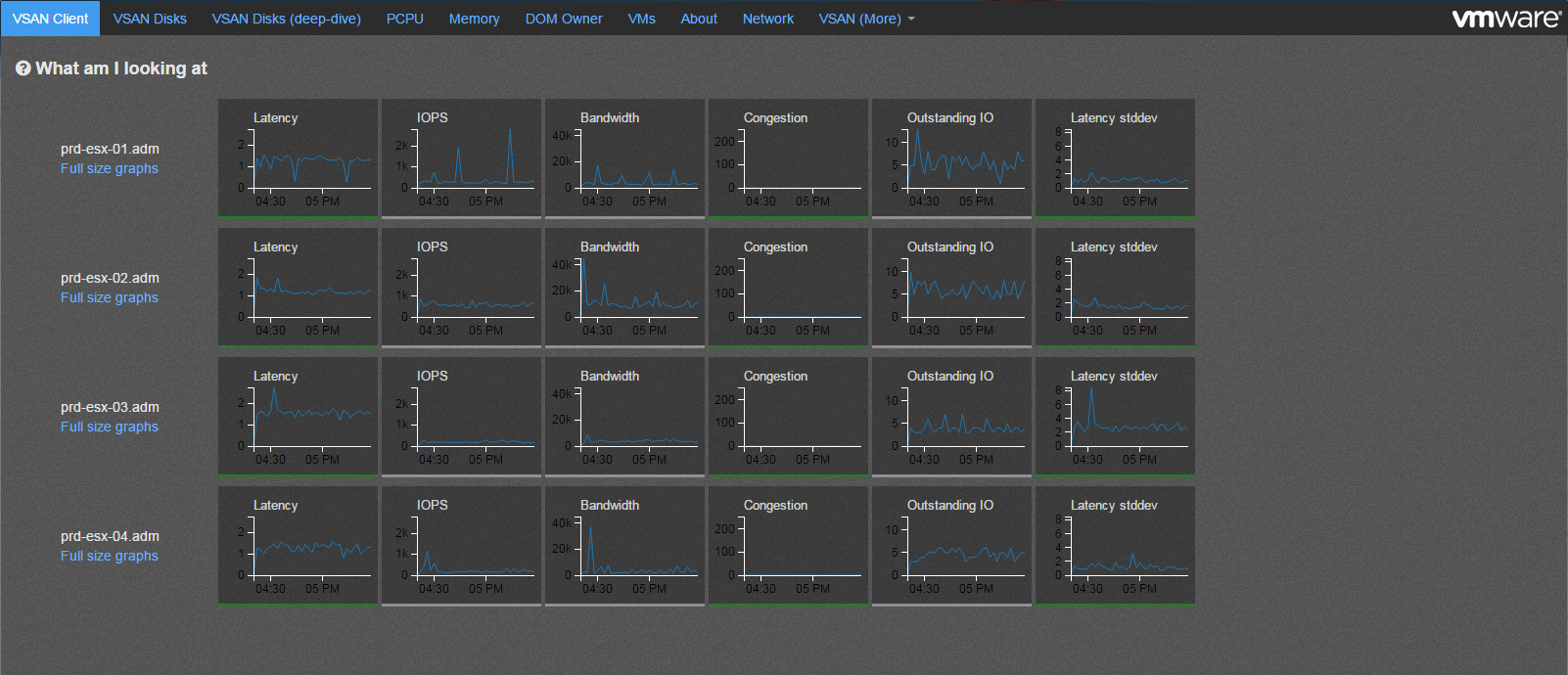
But unlike vSAN Observer, SexiGraf makes vSAN Monitor persistent because when you need it you most likely want to know what just happened. Since you have to launch vSAN Observer and wait few minutes, that particular moment is gone. vSAN Monitor let you explore 6 months from now so you can relax.
Nevertheless, vSAN Monitor is NOT a replacement for vSAN Observer since it only offers the primary “tabs” where you’ll be able to check the global activity of your vSAN cluster per nodes. When you need to deep dive, you’ll still need vSAN Observer. Even if it’s now deprecated…
Since some brillant guys at VMware already explain how to read vSAN metrics, you’ll need to check those papers if you not already did : Monitoring VMware Virtual SAN with Virtual SAN Observer & VMware Virtual SAN Diagnostics and Troubleshooting Reference Manual.
The layer label let you switch beetween vSAN layers described in the vSAN Observer help section:
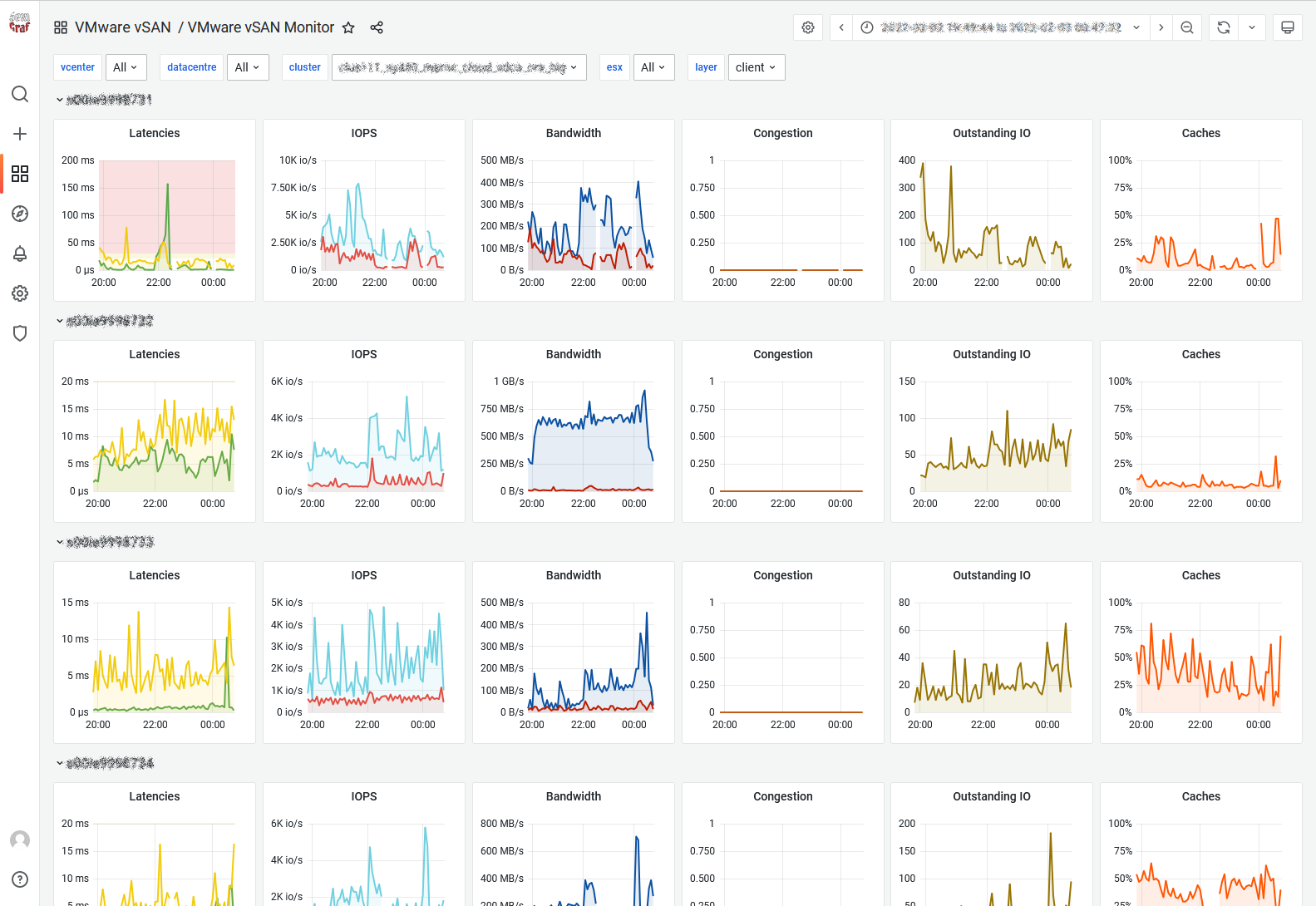
Client: This view shows vSAN statistics from the view point of the vSAN client running on each host. In other words, this view represents the vSAN performance as seen by VMs running on the hosts for which statistics are shown.
If this view shows any unexpected performance, one needs to drill down further to understand where performance issues may be coming from. It is important to understand that due to the distributed nature of vSAN each host accesses data from all hosts, so any performance issue seen on this view may be caused by any host in the vSAN cluster.
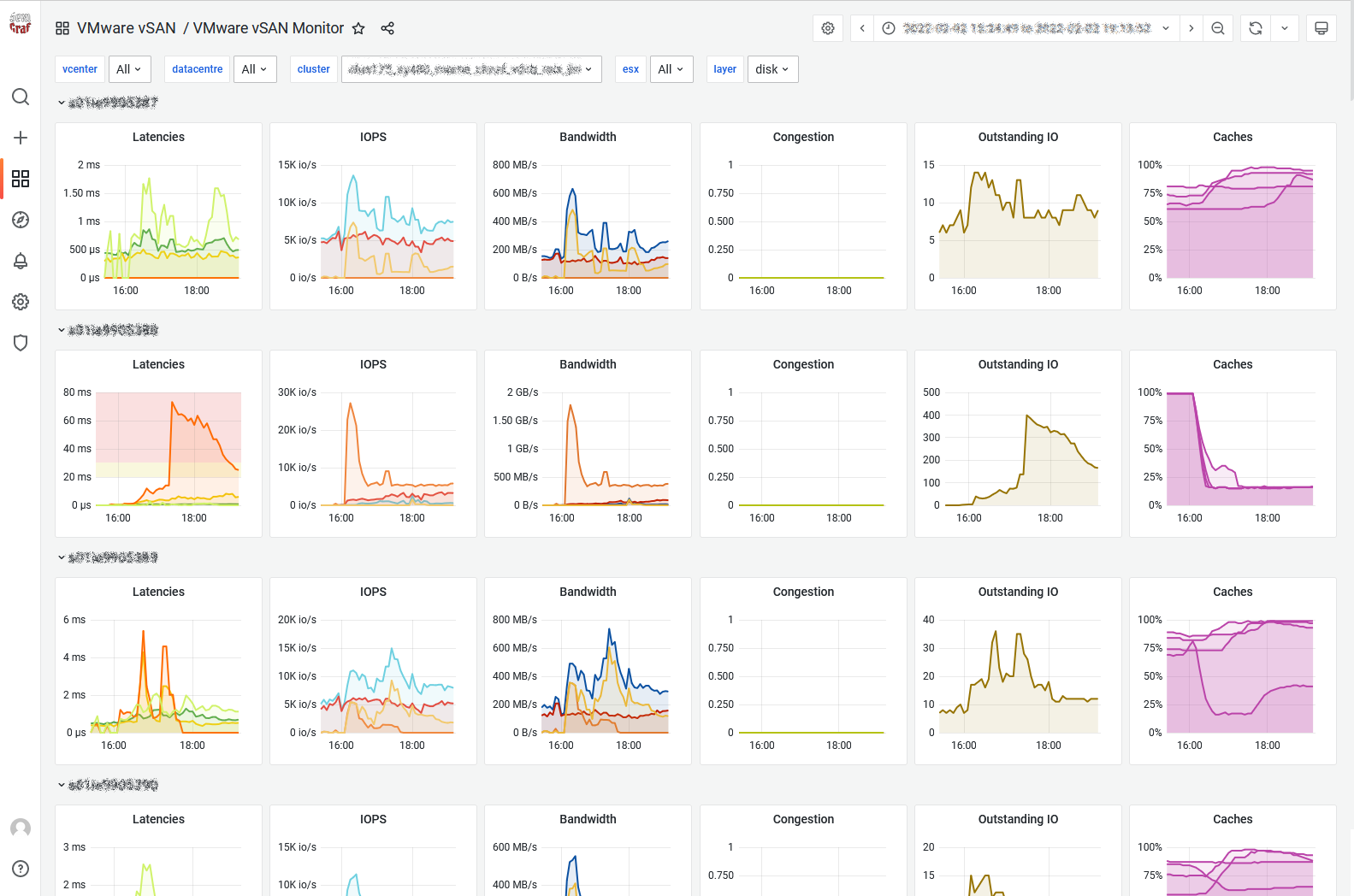
Disks: This view shows vSAN statistics of the physical disk layer of each host. In other words, this view allows to determine if there is any contention on any of the disk groups that make up the overall vSAN cluster. Note that the statistics shown are purely the physical disk layer and do not include any other vSAN overhead (e.g. networking or vSAN RAID). Also remember that due to the distributed nature of vSAN the physical disks of one host are accessed by VMs on all hosts in the vSAN cluster.
If this view shows physical disk contention across a majority of hosts then this likely indicates that the workload run by VMs is collectively higher than the vSAN cluster can handle. In that case, either reduce the storage workload, or check the detailed physical device view to determine if you need more HDDs or SSDs.If however only a single host’s physical disks are contended, while other hosts are operating fine, then you may have an imbalance, e.g. caused by particularly noisy VMs.
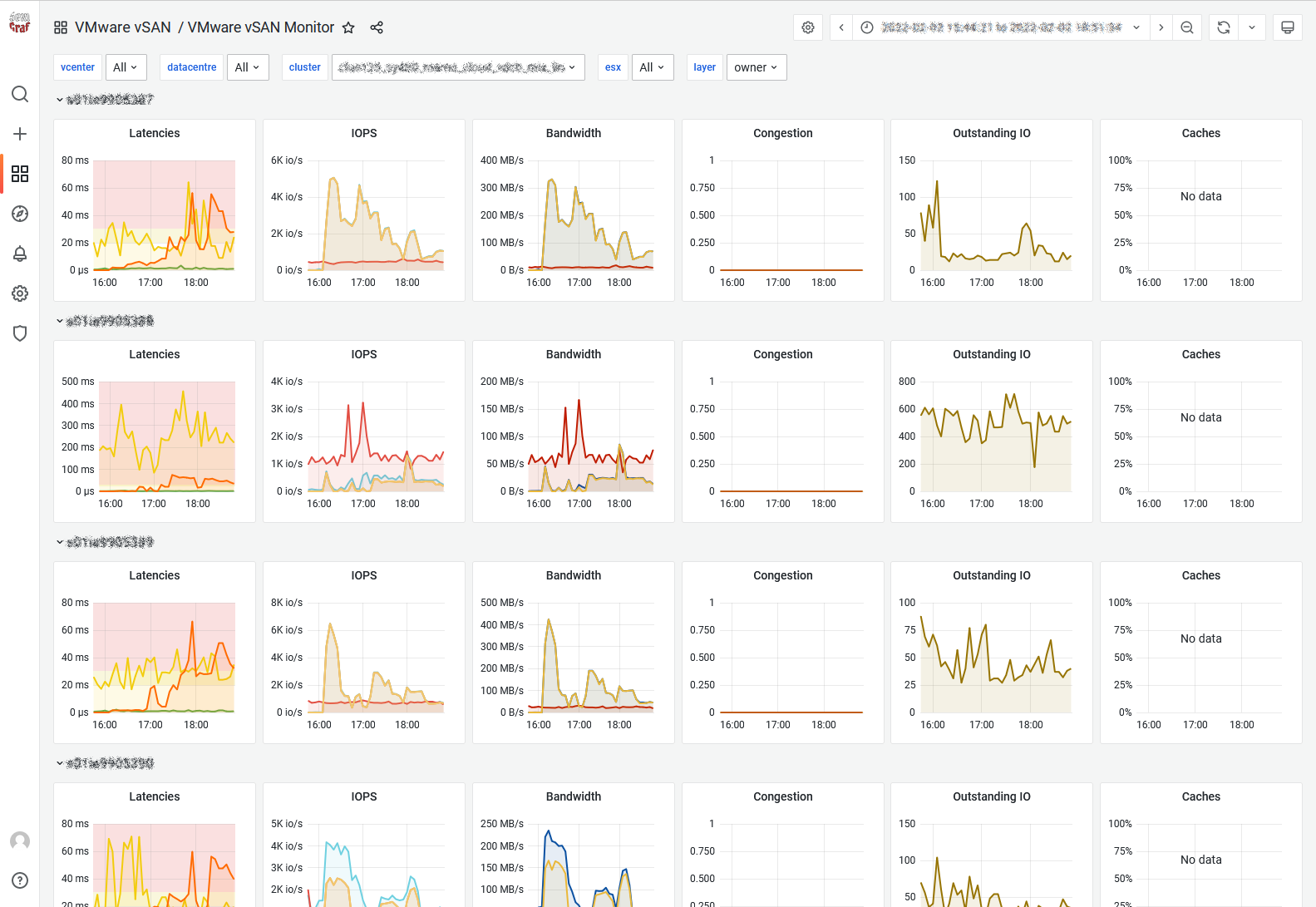
Owner: The DOM owner is a vSAN internal layer. For every vSAN object vSAN elects one host to be the ‘owner’. The owner performance all RAID functionality and ensures correctness, even under concurrent access by multiple clients. All IO flows from the vSAN client to the owner and then to the disk layer. vSAN tries to co-locate the owner and the client to not incur an additional network hop. However, the user can’t influence where the owner for a given object is located, so reading the below graphs and correlating them with the client and disks graphs can be very difficult.
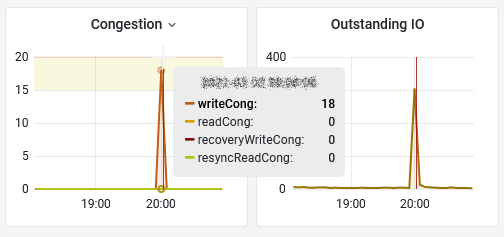
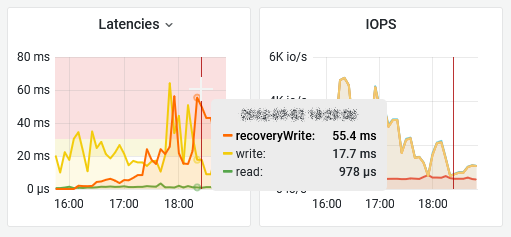
You may have noticed the last column is not Latency stddev but Caches stats (Client Cache or Write Buffer) since we believe it offers a more syntetic view. We also got thresholds like vSAN Observer but Grafana’s are areas so you know exaclty when the metric hits the roof and for how long. As per vSAN Observer settings, the threshold for latency is 30ms, 20 for congestion and 30 for latency SD.
We also added colors 😉
Support for vSAN 6.6 APIs has been added to SexiGraf 0.99d so for those having ESXi 6.5.0d+ vSAN cluster with v5 on-disk format, introducing the new resyncRead, client.cachestats metrics and Recovery Write.
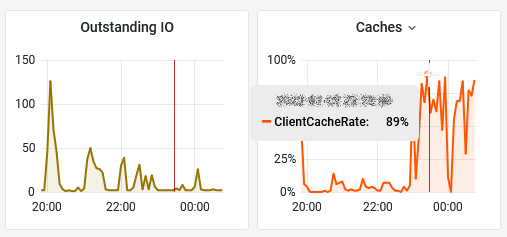
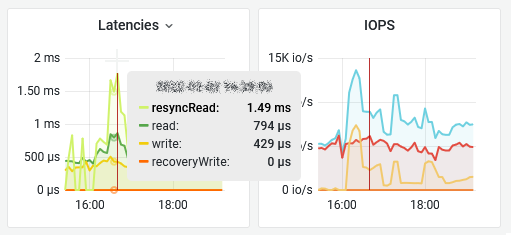
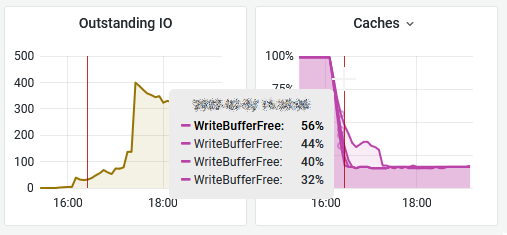
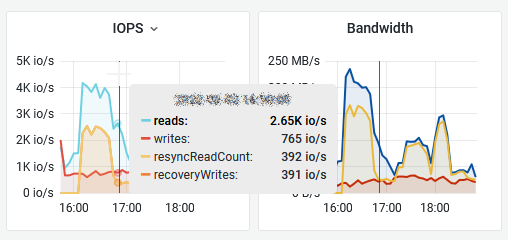
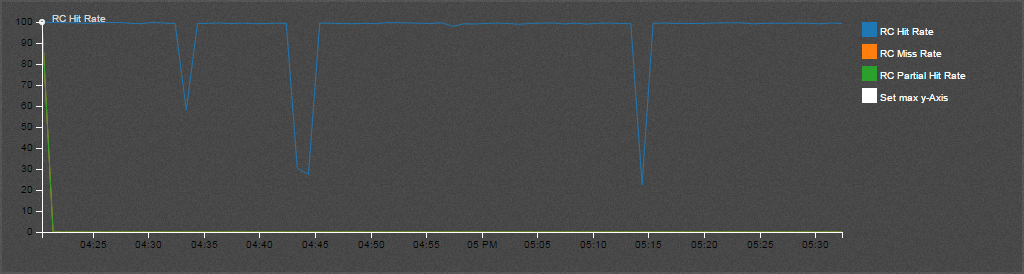
The new client cache was introduced in vSAN 6.2 but not exposed in the public APIs until vSAN 6.6 release.
As of 6.2 vSAN also has a small in-memory read cache. Small in this case means 0.4% of a host’s memory capacity up to a max of 1GB. Note that this in-memory cache is a client side cache, meaning that the blocks of a VM are cached on the host where the VM is located.
vSAN Monitor SFTT
As described in VMware vSAN 6.6 Technical Overview white paper, vSAN 6.6 introduce secondary level of failures to tolerate (SFTT) for stretched clusters:
Starting with vSAN 6.6, it is possible to configure a secondary level of failures to tolerate. This feature enables resiliency within a site, as well as, across sites. For example, RAID-5 erasure coding protects objects within the same site while RAID-1 mirroring protects these same objects across sites.
After snooping into the undocumented metrics, we discovered that the SFTT traffic is “monitorable” through 2 new counters called “proxy” and “anchor” so, starting from v0.99d, we added a dedicated dashboard inspired from the vSAN Monitor one. But since we discovered that it’s considered as a layer in the API we integrated the SFTT stats into the “proxy” layer in SexiGraf 0.99h:
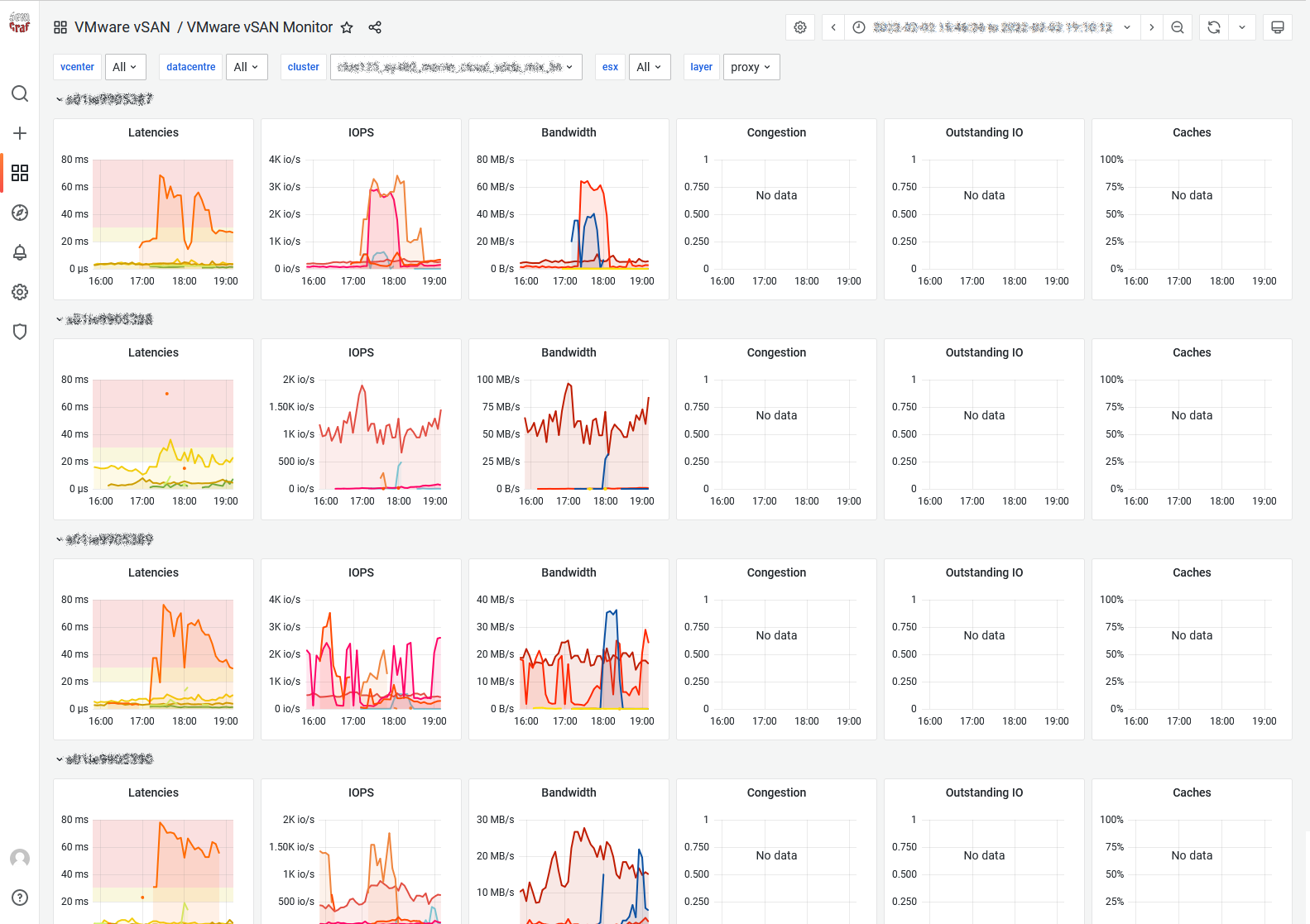
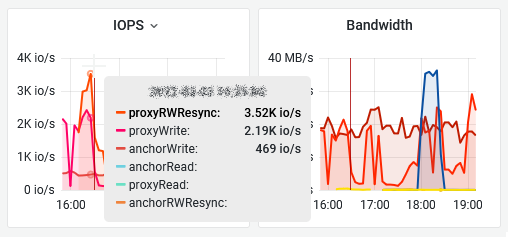
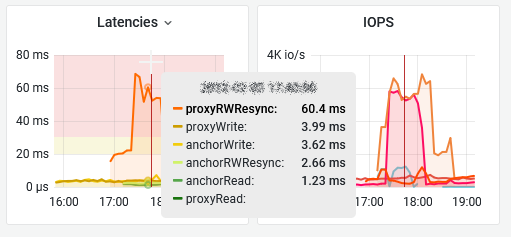
vSAN Resync & Health
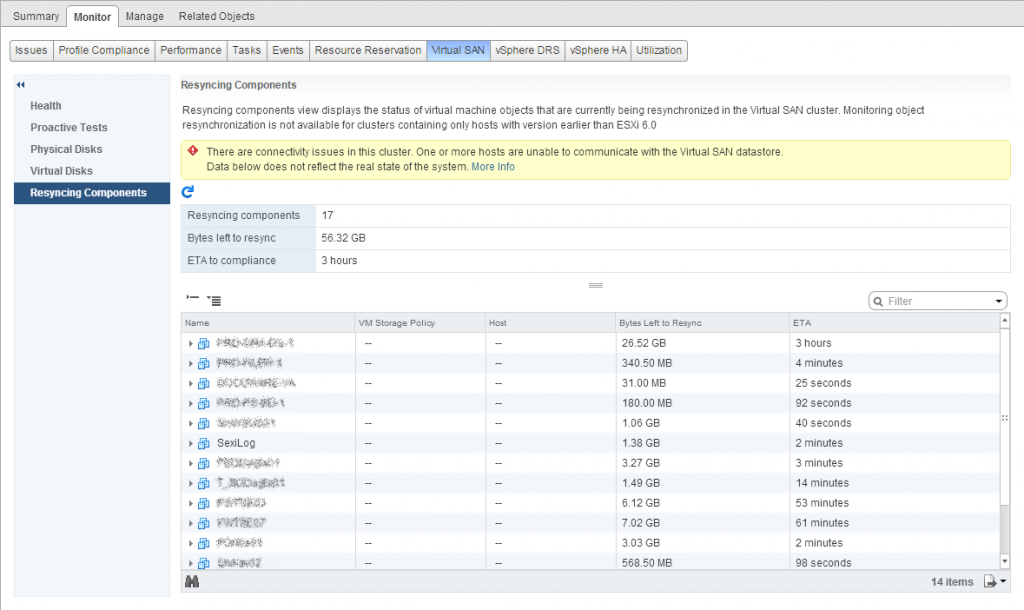
Instead of endlessly clicking on the refresh button in the “Resyncing Components” tab of the WebClient, we added the vSAN Resync dashboard since SexiGraf 0.99b:
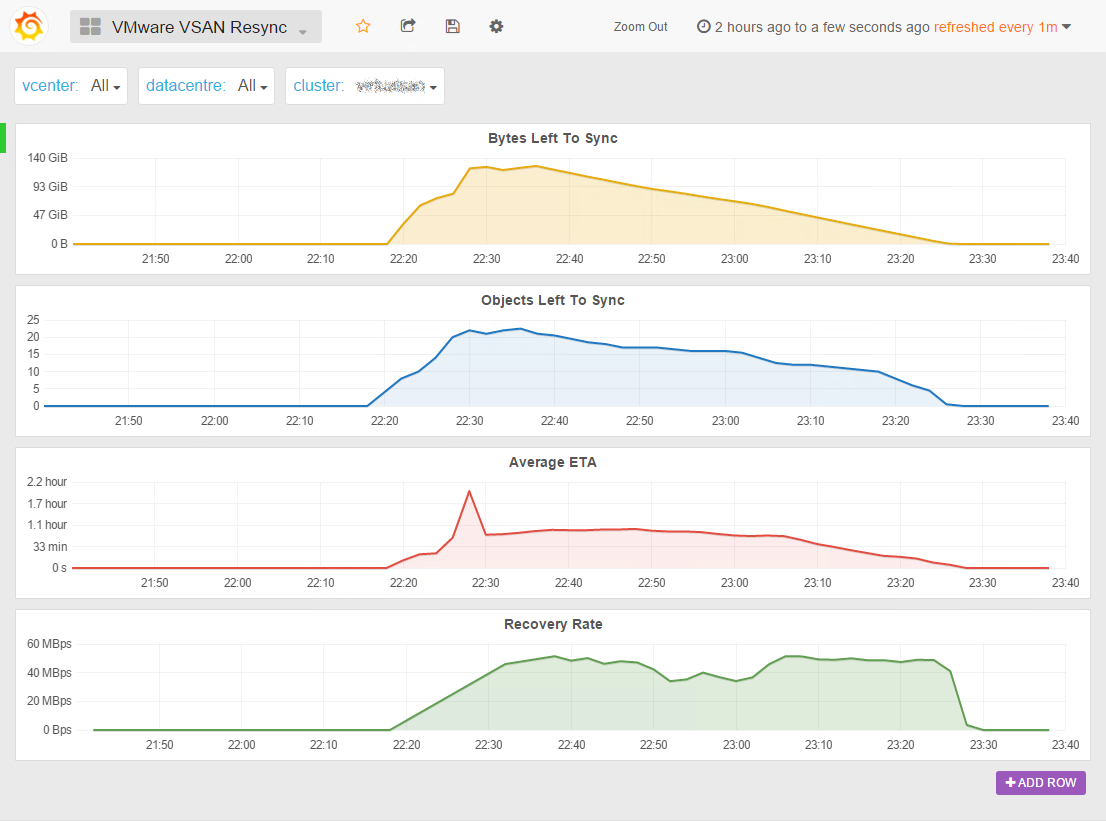
Now you can really see what’s going on when objects are being resynced, rebuilded or rebalanced. We also added a Recovery Rate graph to check how fast your vSAN backend performs.
Starting from version 0.99e, we pushed even further and leveraged the vSAN 6.7 API when available. In vSAN 6.7 VMware introduced the Sync State Reason so you also know WHY the components are being (re)sync. And if some components are synced for several reasons, you’ll know it too of course. Only in SexiGraf 😉
The list of reasons indicate why the component went into syncing state. The API returns full list of reasons for background. However, sometimes it’s userful to generate an aggregate reason, in which case the following priorities could be used:
P0: “evacuate” ()
P1: “dying_evacuate” ()
P2: “rebalance” ()
P3: “repair”, “reconfigure” ()
P4: “stale”dying_evacuate: The component is being moved out when a disk is going to die.
evacuate: The component is created and resyncing after evacuate disk group or host to ensure accessibility and full data evacuation.
rebalance: The component is created and resyncing for rebalancing.
reconfigure: The component is created and resyncing after vSAN object was resized or its policy was changed.
repair: The component is created and resyncing to repair a bad component.
stale: The component is syncing because it was stale.
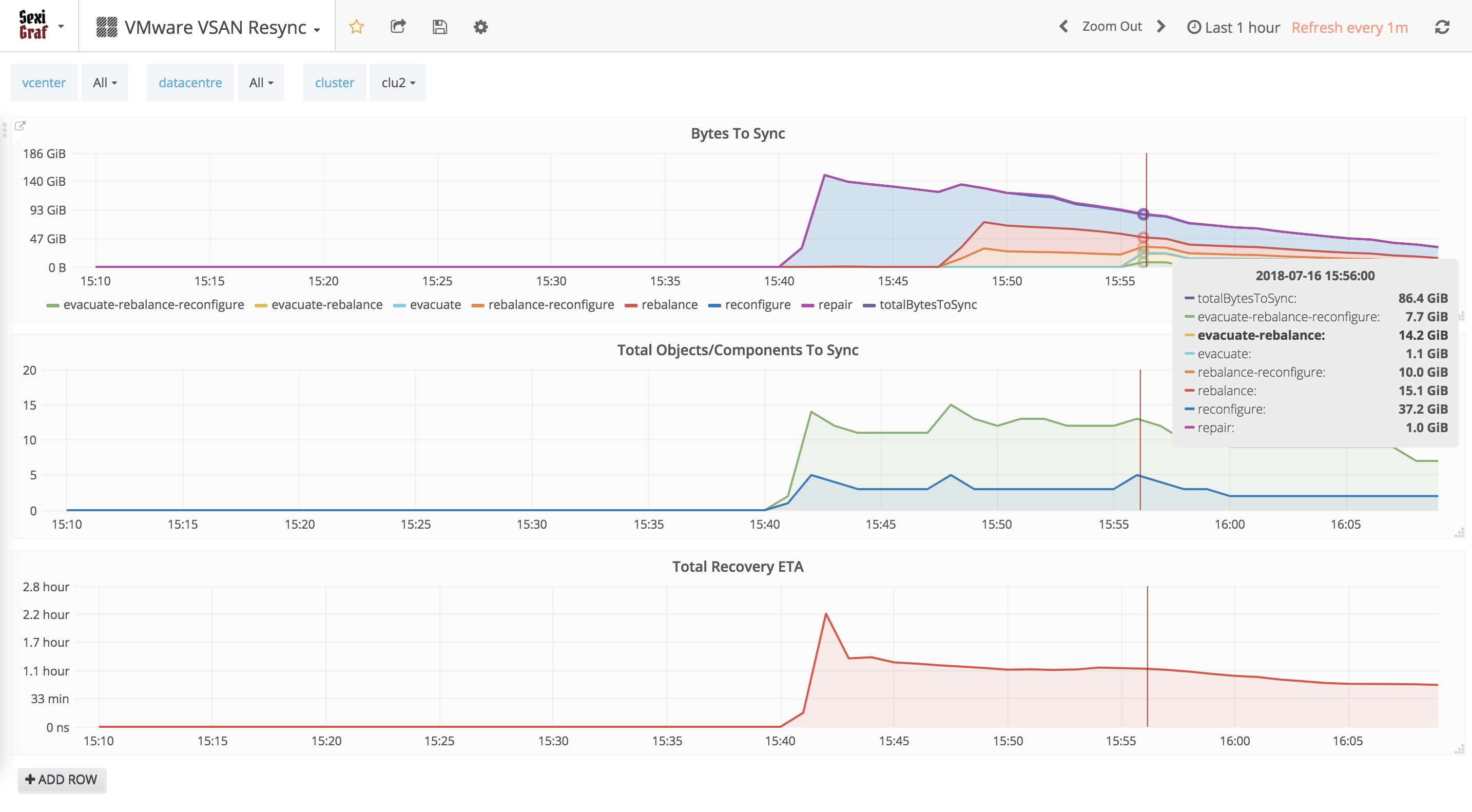
In SexiGraf 0.99h we renamed and introduced a new graph in this dashboard : Object Health
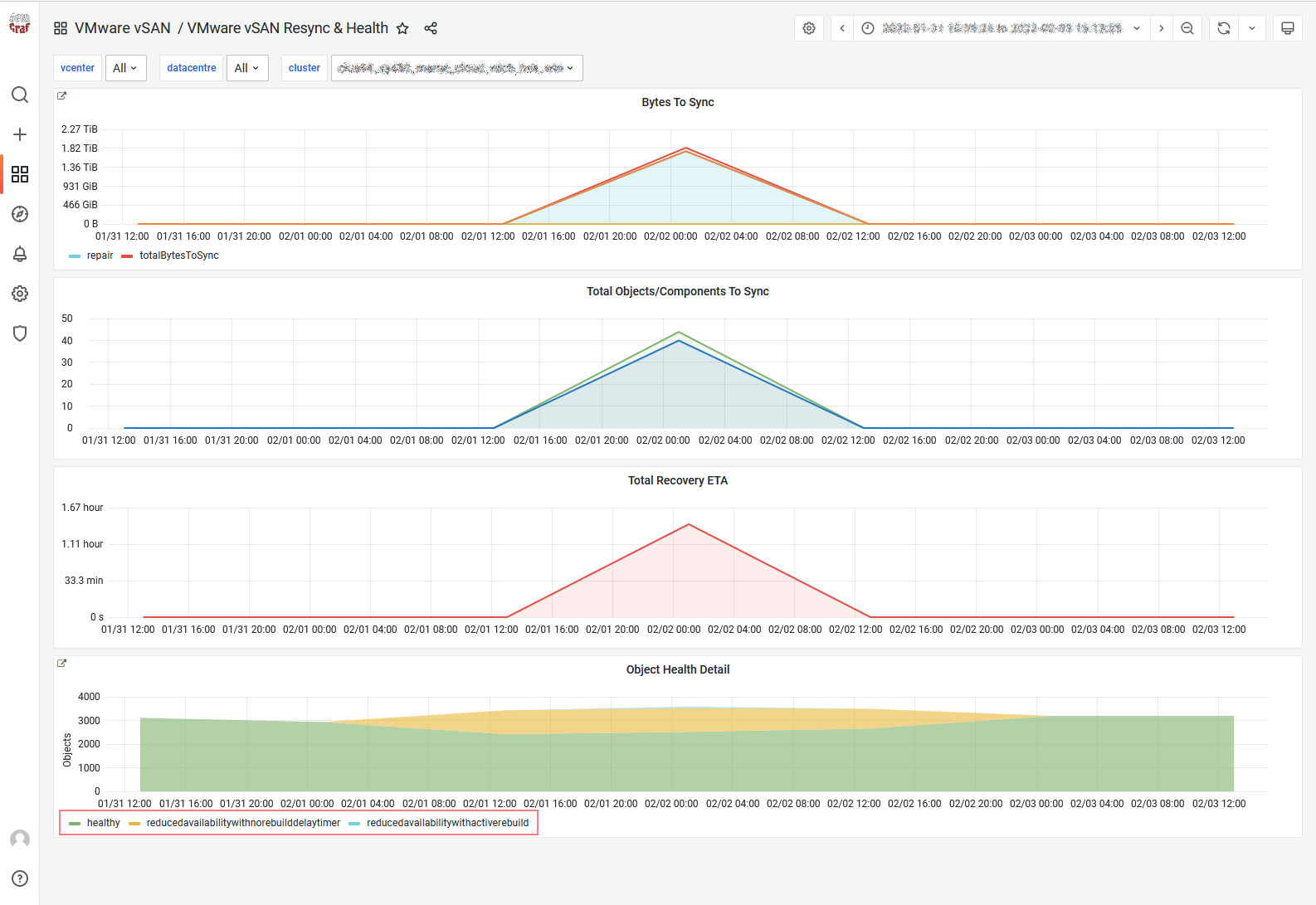
Now you can monitor the health status of your vSAN cluster objects in real time but also in the past! Here is an extract of the various you might encounter with:
datamove
healthy
inaccessible
nonavailabilityrelatedincompliance
nonavailabilityrelatedincompliancewithpausedrebuild
nonavailabilityrelatedincompliancewithpolicypending
nonavailabilityrelatedincompliancewithpolicypendingfailed
nonavailabilityrelatedreconfig
reducedavailabilitywithactiverebuild
reducedavailabilitywithnorebuild
reducedavailabilitywithnorebuilddelaytimer
reducedavailabilitywithpausedrebuild
reducedavailabilitywithpolicypending
reducedavailabilitywithpolicypendingfailed
remoteAccessible
VsanObjectHealthState_Unknown
In v0.99k we added the “Cluster Health Score” metric from vSAN 8.1 with a bit more style and color 😉

vSAN Disk Latency
The vSAN Disk Latency dashboard (added in SexiGraf 0.99b) let you check the individual latencies of every single device in the vSAN cluster sorted by Network Addressing Authority identifier.
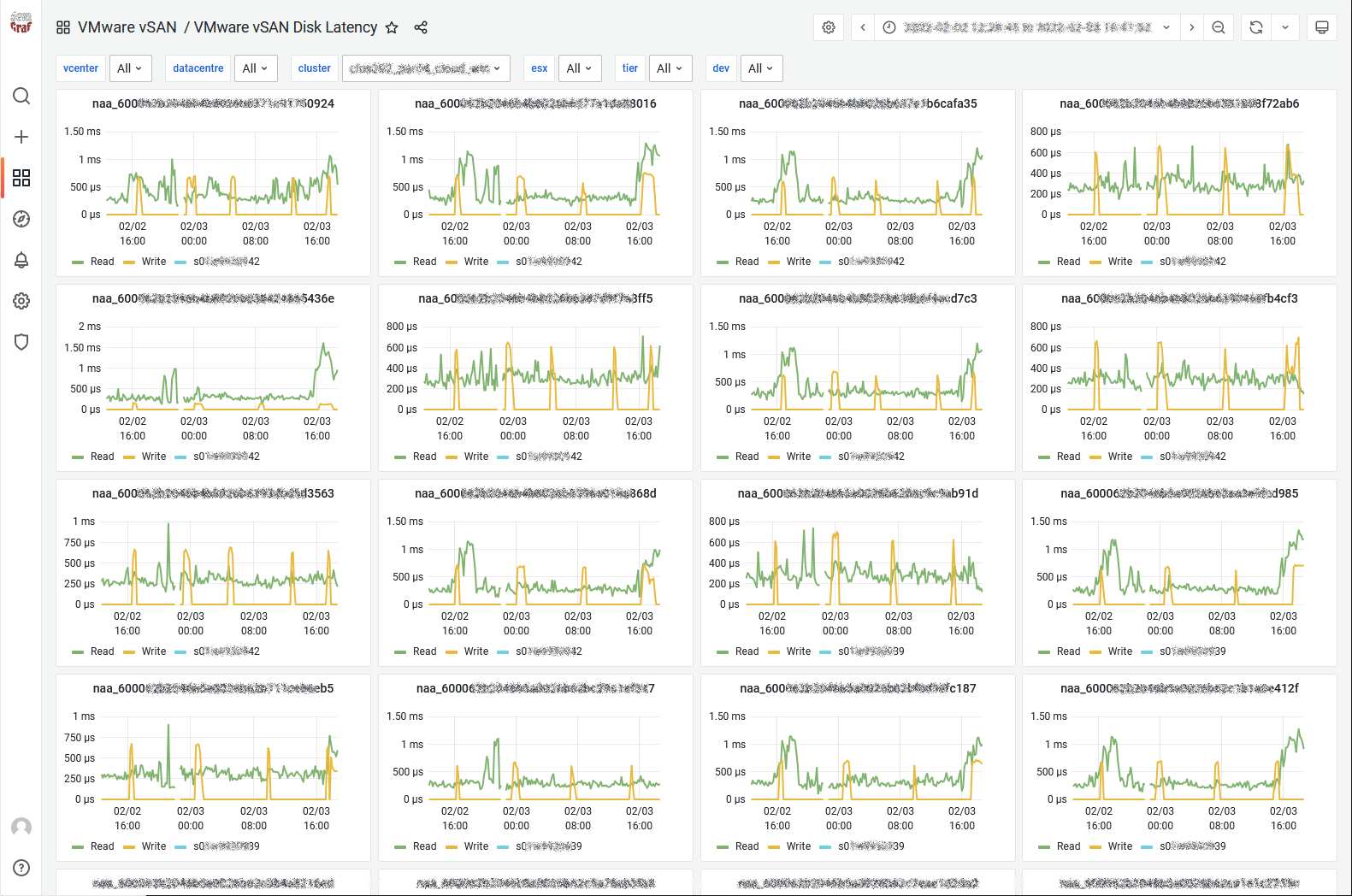
In 0.99h we added the possibility to filter between the cache and the capacity tier so you can compare the latencies across the WHOLE cluster and maybe spot a nasty rogue Optane device about to die (and solve why your cluster is acting so weird lately):
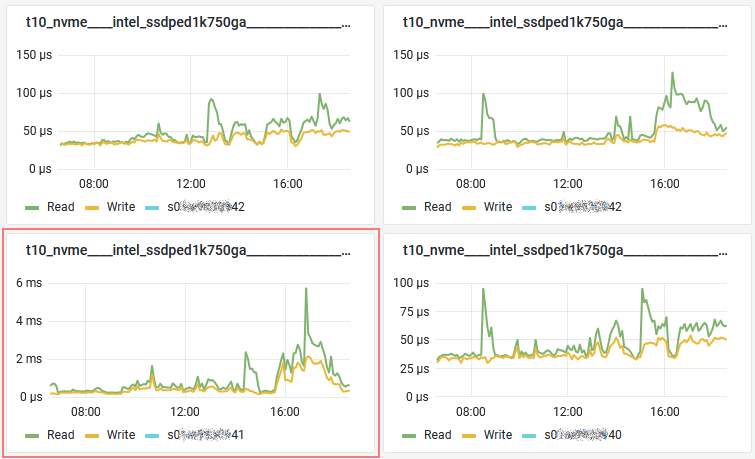
In 0.99i we added support for vSAN Express Storage Architecture which doesn’t require any dedicated cache device anymore (no more diskgroups) so you’ll find all your devices under the capacity tier.
vSAN Space Usage Report
SexiGraf 0.99c ships with vSAN 6.2 SDK enabling new kind of dashboards. vSAN Space Usage Report aims to enhance the vSAN Capacity tab in the vSphere Client:
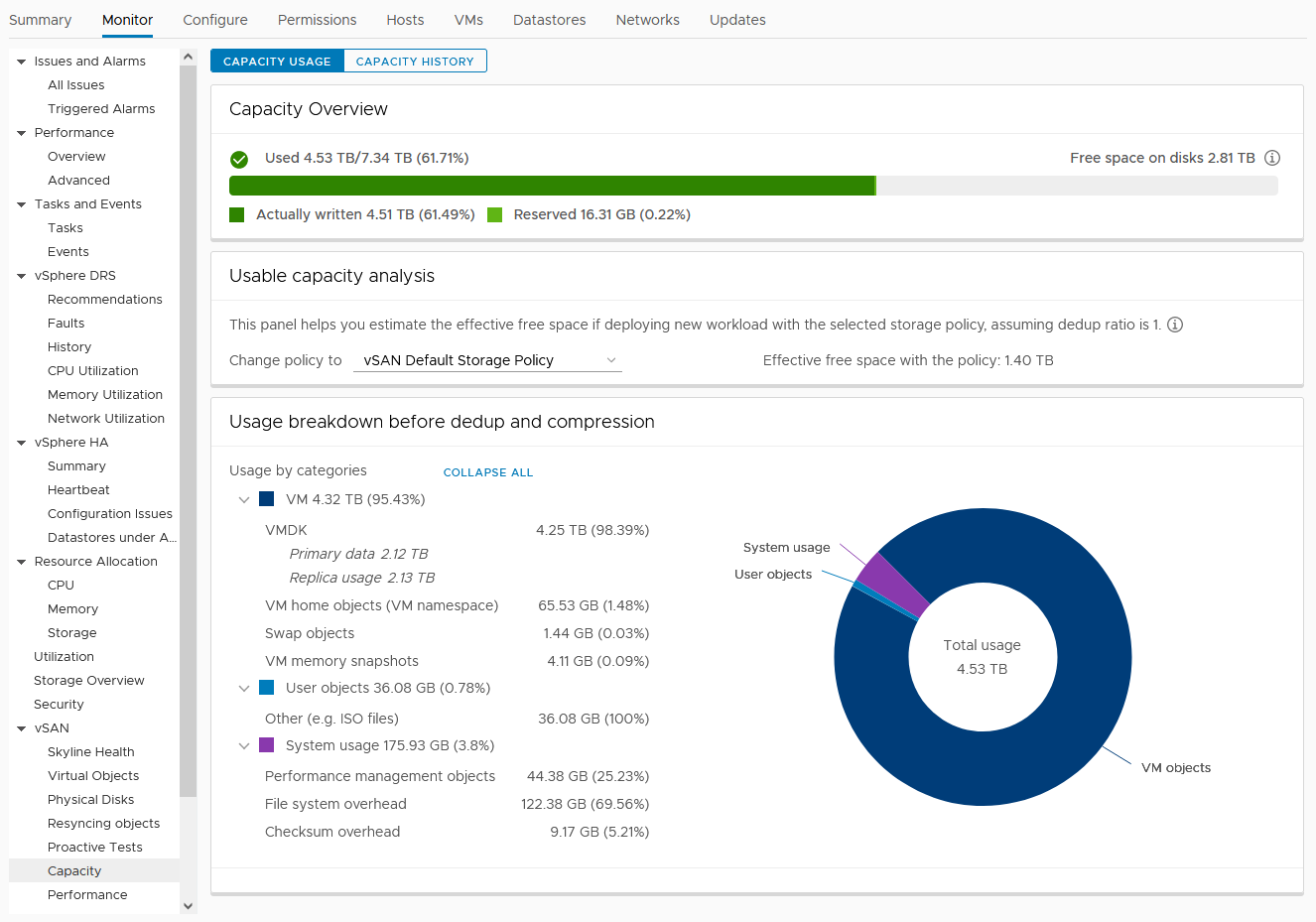
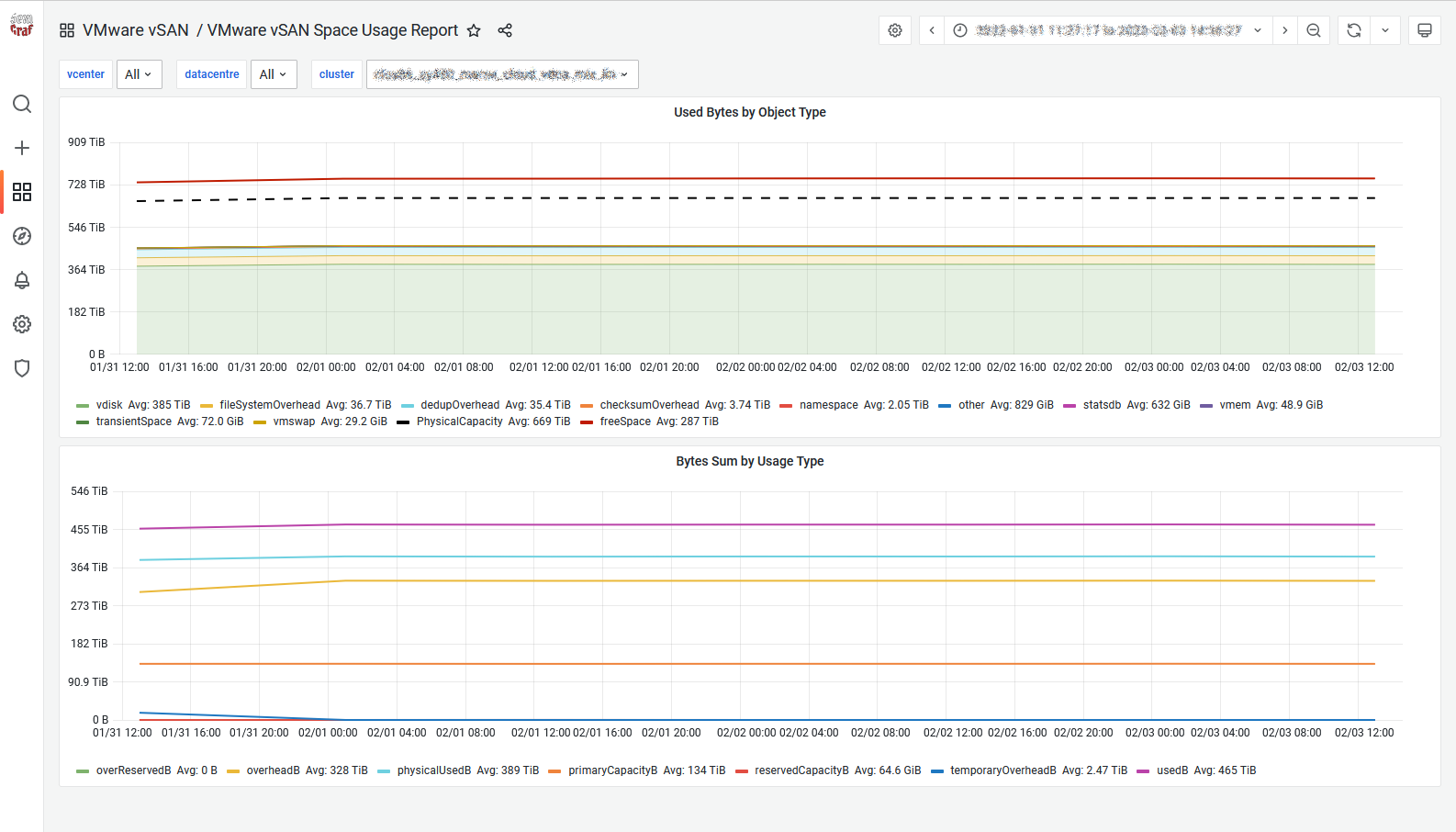
You should check the excellent Cormac’s blog post regarding the role of each object type but also the SDK documentation to match the “internal” property names. If the freeSpace value is higher than the PhisicalCapacity, it means you’re using the deduplication and/or compression feature(s) of vSAN.
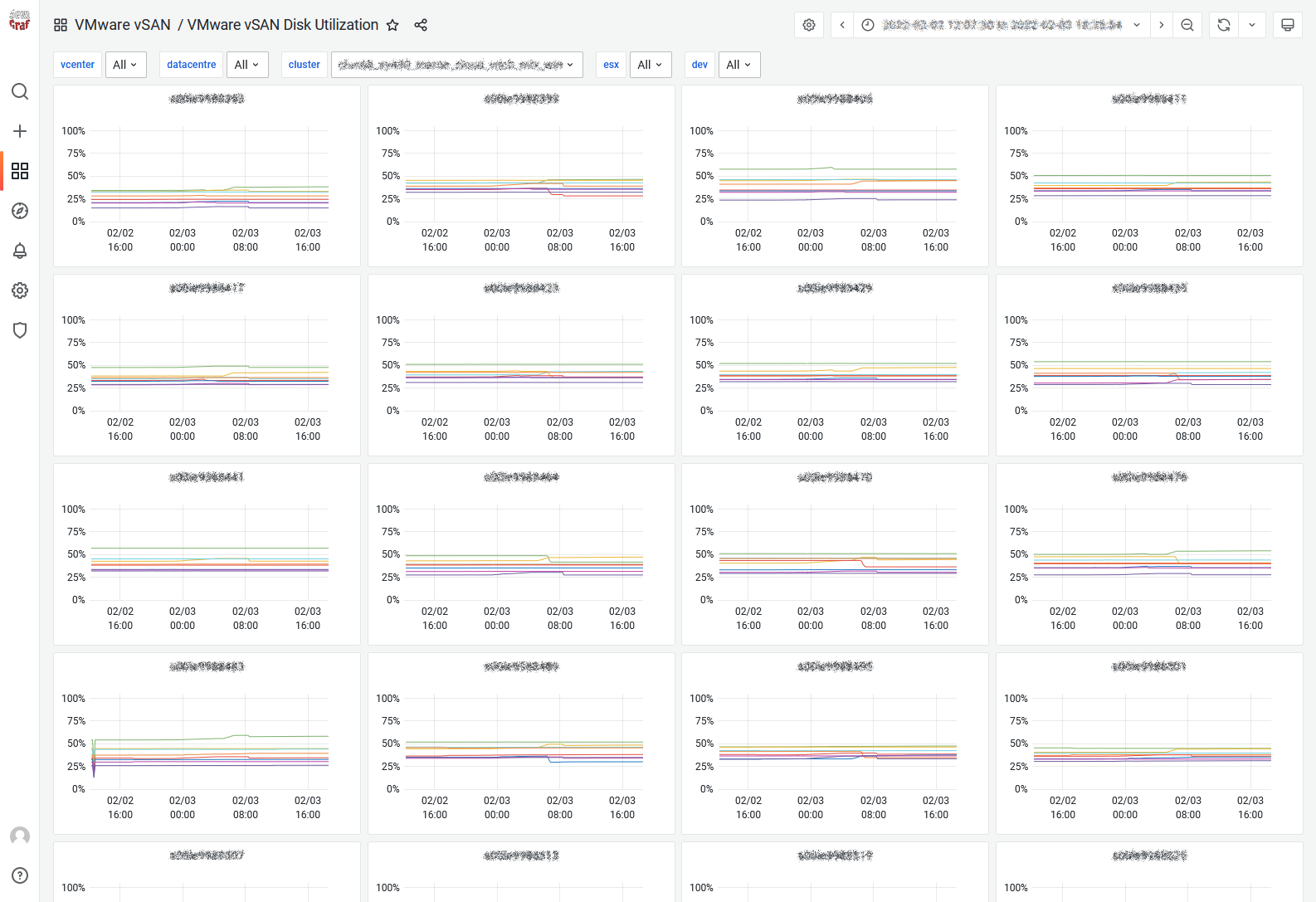
vSAN Disk Utilization
When you would need to monitor the space consumption at the device level across the entire cluster, the Disk Utilization dashboard is perfect.
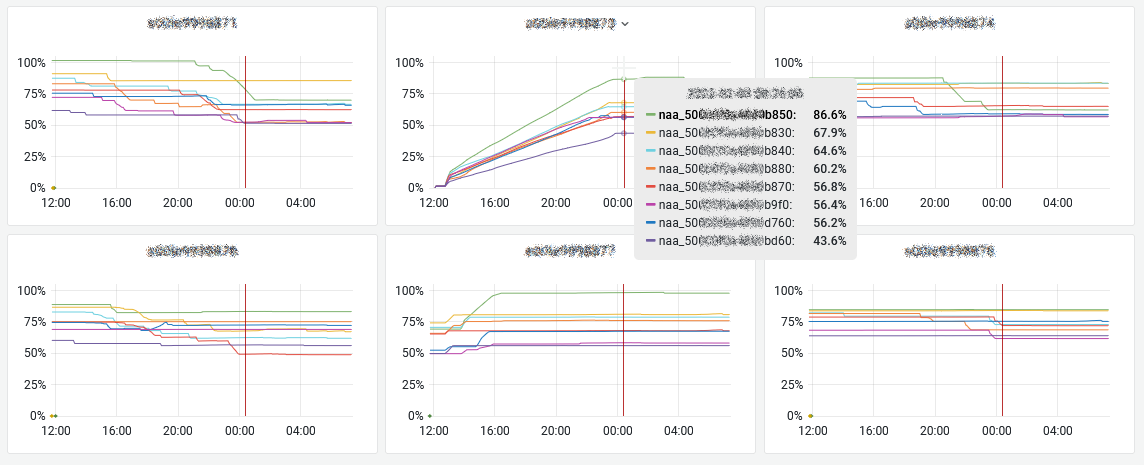
For instance, when you re-add a node to a cluster after a full evacuation, it’s critical to be able to follow the ongoing process:
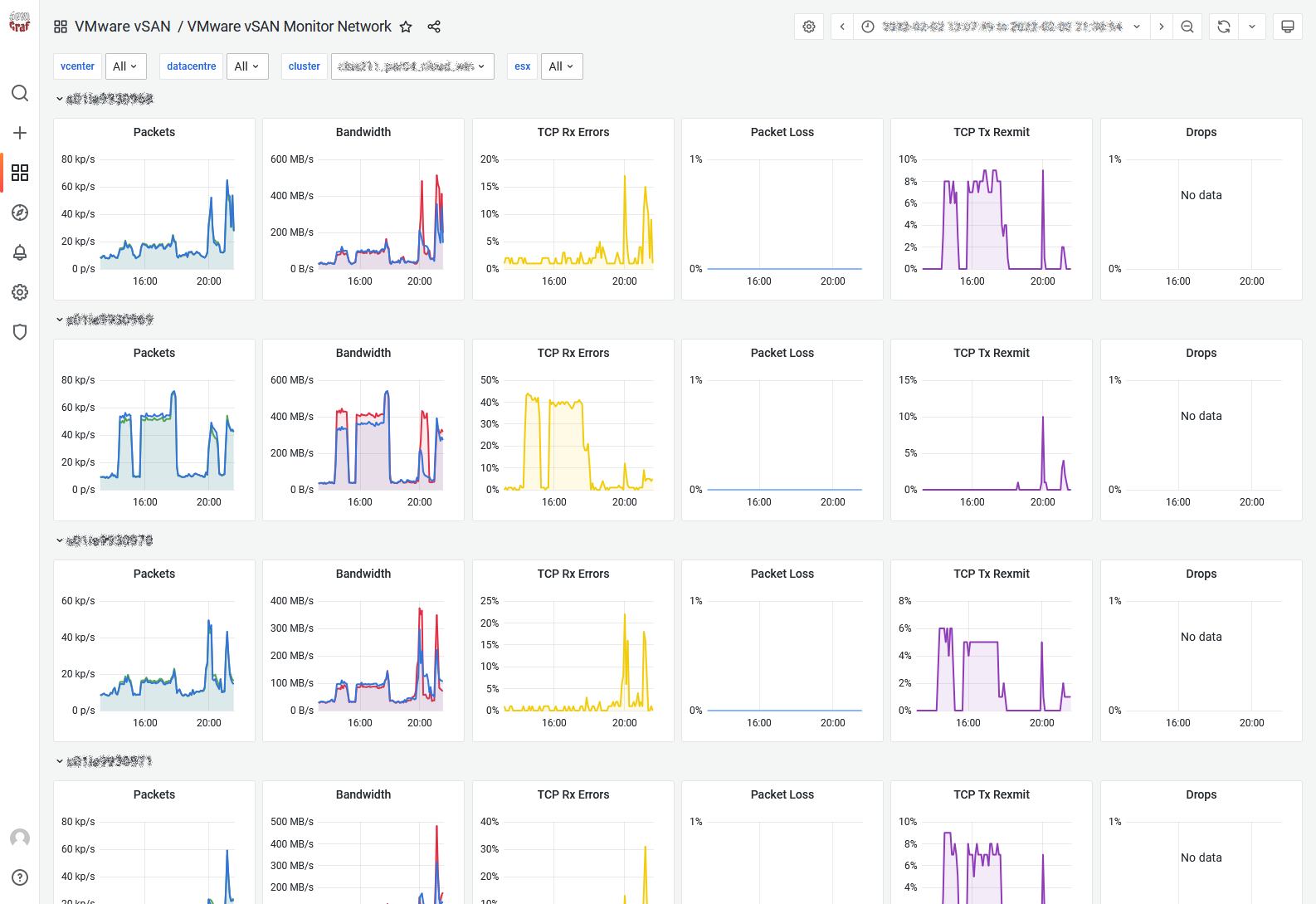
vSAN Monitor Network
Since vSAN relies almost entirely on its network, we have to know if there is any issue going on during the data transmission. This visibility is even more critical when you manage vSAN stretched clusters. For that, the vSAN Monitor Network offers the essential basics: network I/O, bandwidth, drops, loss and retransmissions.
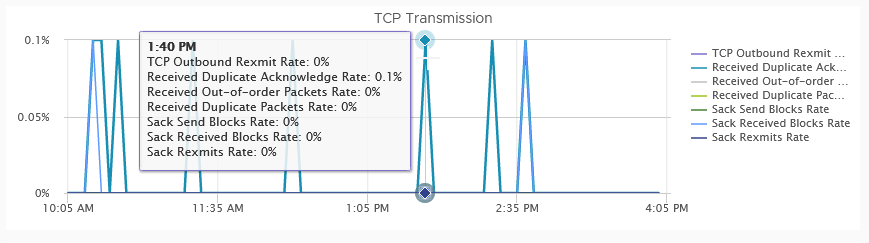
If you need more, the TCP/IP dashboard of the Performance for support tab has some interesting counters like out-of-order, duplicates and SACK:
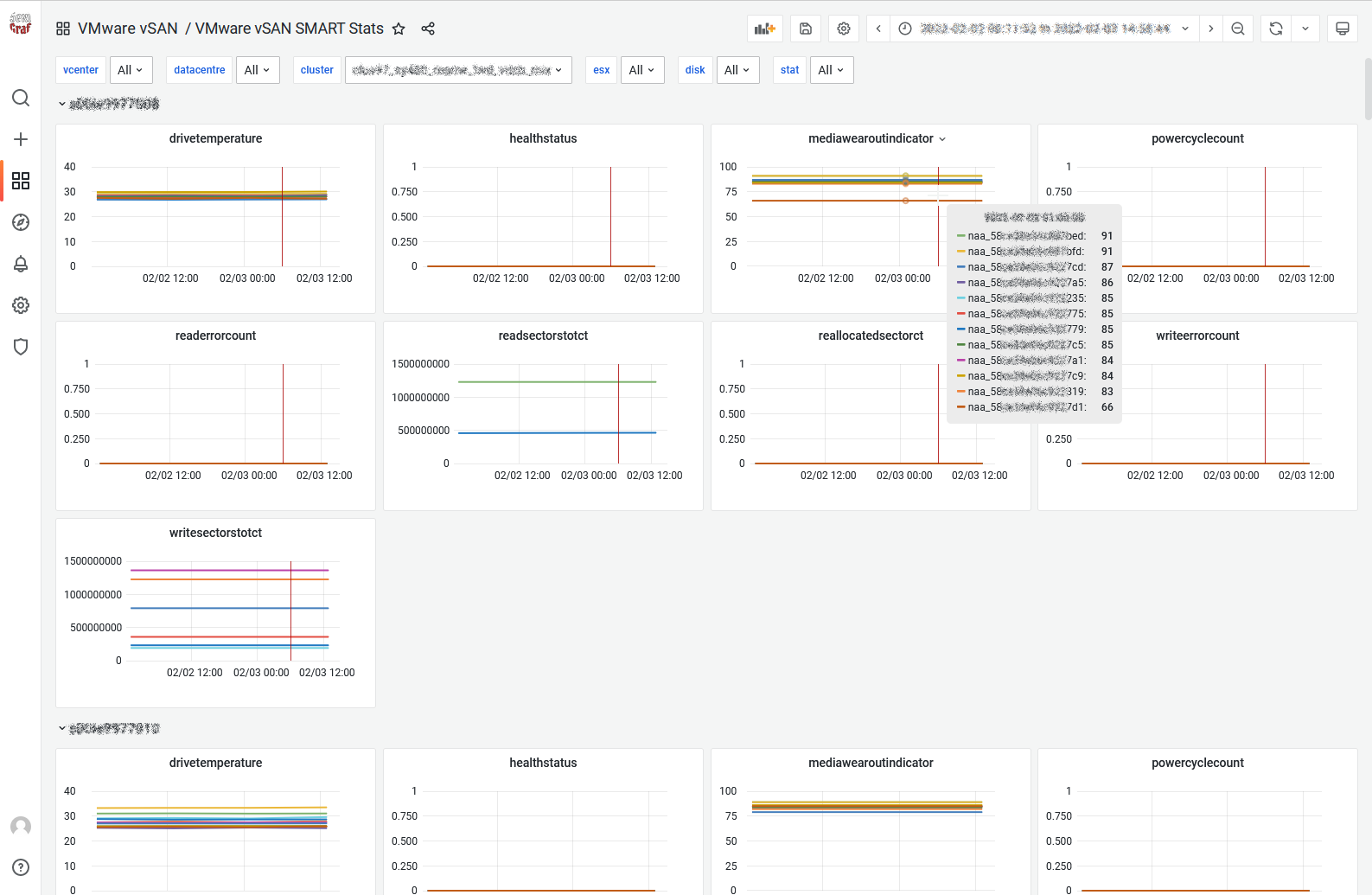
vSAN SMART Stats
Some users asked us if they could monitor the SMART counters since they had “surprises” in the past. Since a new API has been introduced in vSAN 6.6 we figured it would make sense.
SexiGraf 0.99h introduce a new dashboard where you can monitor every counters of every devices in your vSAN clusters: